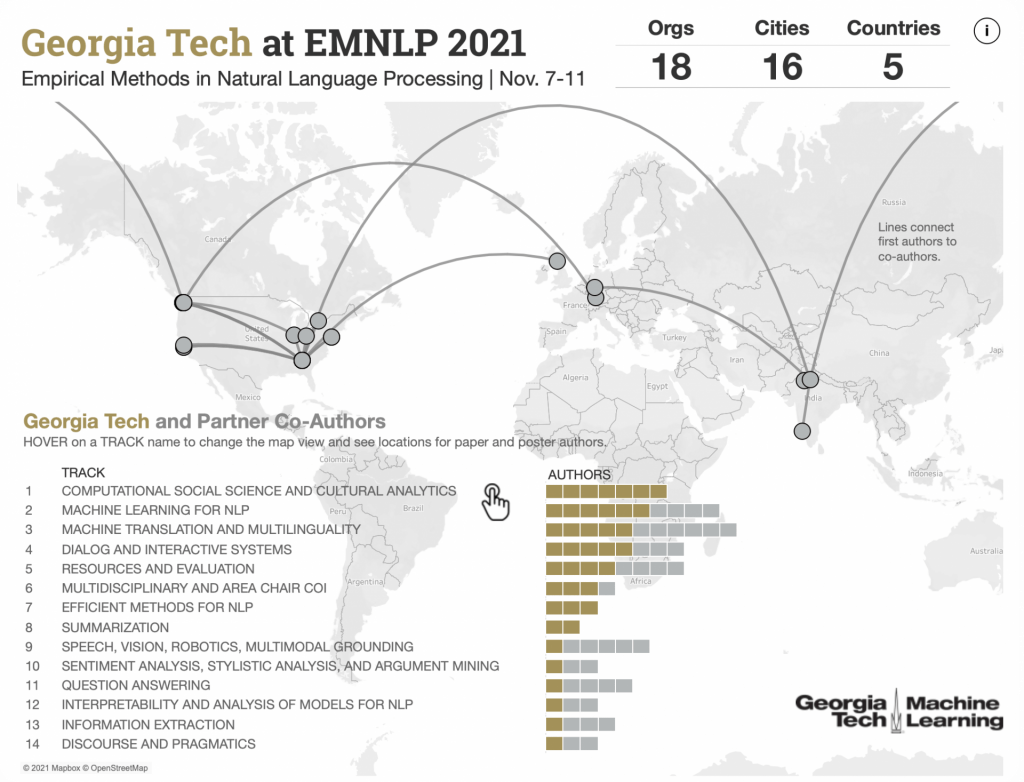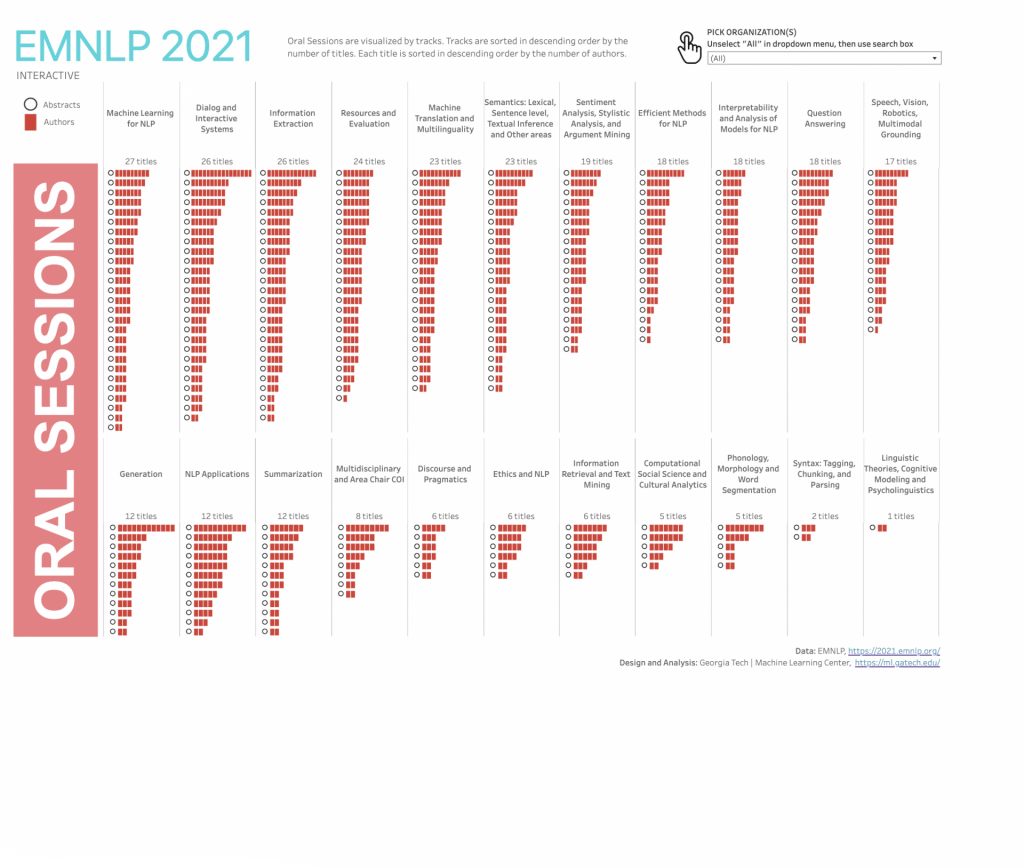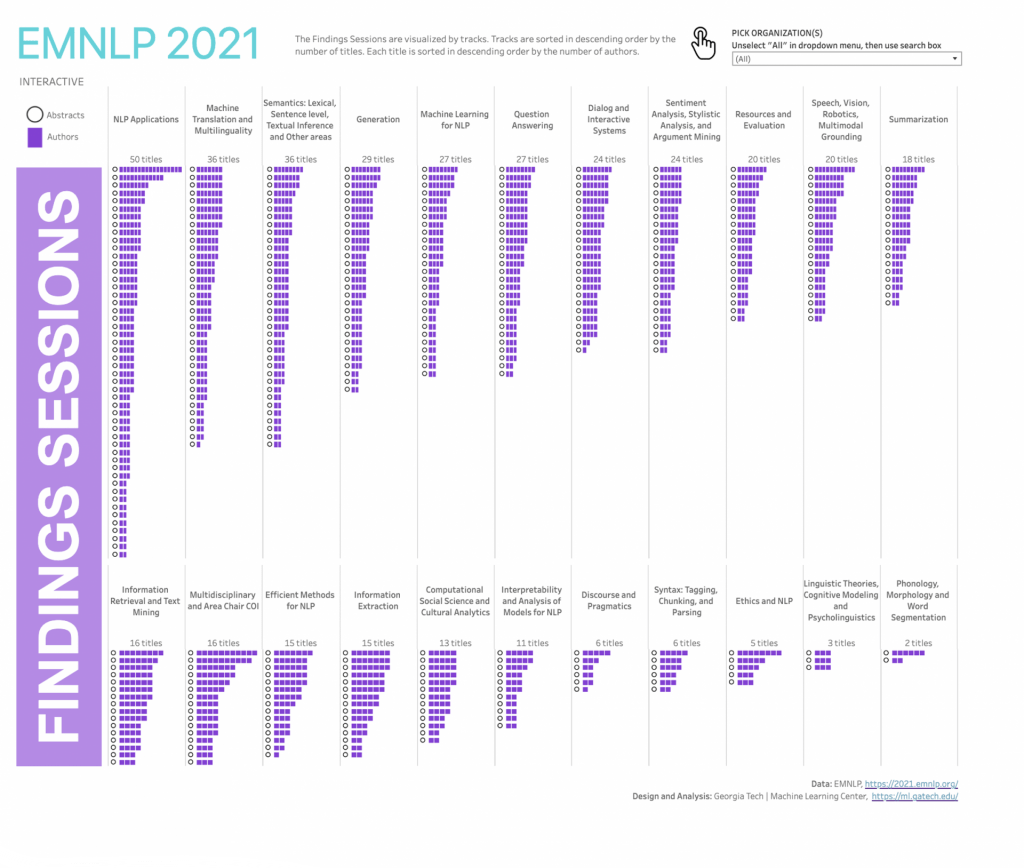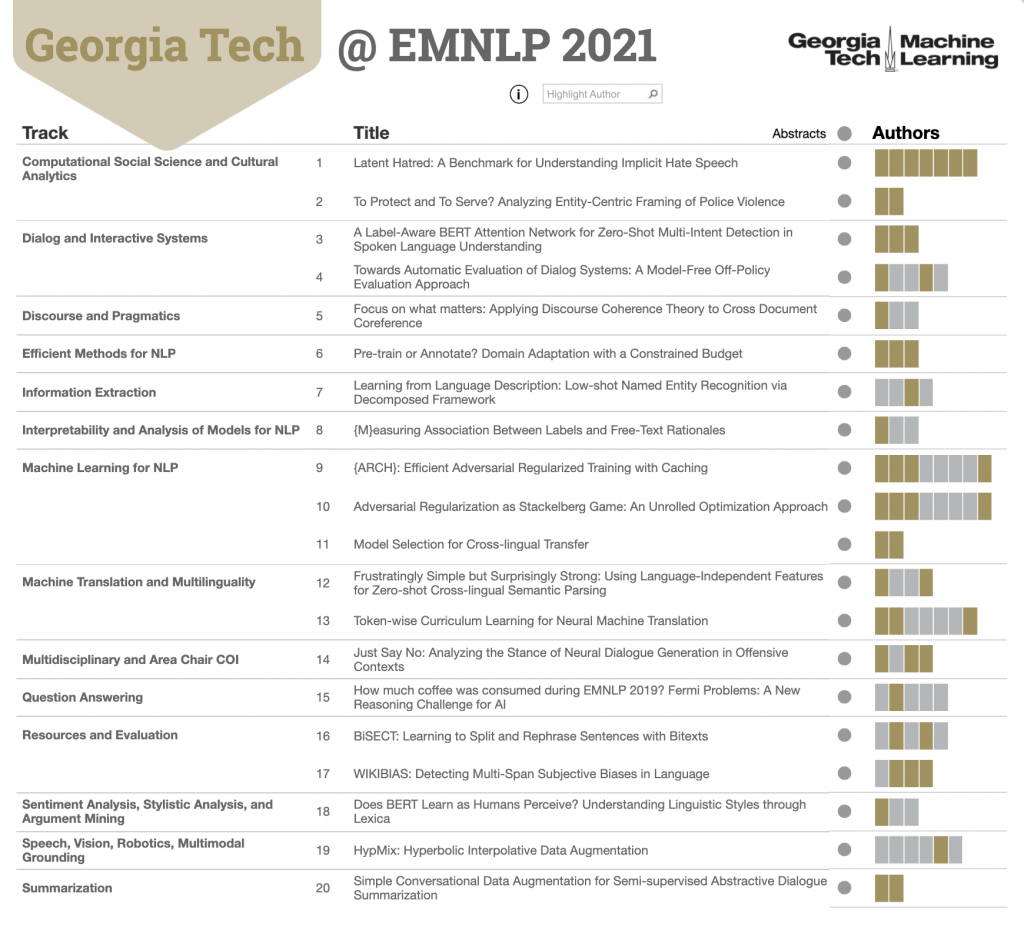
Georgia Tech research papers include natural language processing work from across the EMNLP program. Explore all the people and individual papers by clicking the data graphic. Georgia Tech’s 28 authors in the program contributed to 18 long papers and two short papers.